Class Imbalance Problem in Classification Domain
Class Imbalance is the problem of Machine Learning [Classification Models], when the data is skewed on the target variable, means that there is more data for 1 class [i.e. Majority class] and less for another [i.e. Minority Class], lets say in the ratio of 90:10 can be solved using:
1. Under Sampling Approach [on Majority Class]
2. Over Sampling Approach [on Minority Class]
***Here we will be taking about OverSampling Approach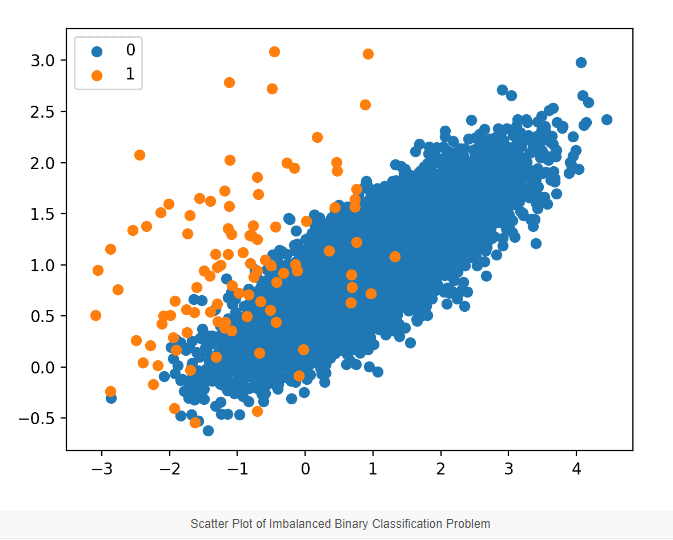
Above chart is for Given Training Data, it clearly shows data for 2 classes highlighted by colors Orange [1] and Blue [0].
Its evident that data is heavily skewed means too much less data for Orange Dots as compared to Blue Dots.
We can OverSample the Minority Class here using SMOTE.
- OverSampling Techniques are:
- ROSE (Random Over-Sampling Examples)
- SMOTE (Synthetic Minority Oversampling Technique)
- It generates the same number of synthetic samples for each original minority sample.
- ADASYN: ADAptive SYNthetic
- It uses a density distribution, as a criterion to automatically decide the number of synthetic samples that must be generated for each minority sample by adaptively changing the weights of the different minority samples to compensate for the skewed distributions.
Below Diagram shows SMOTE

Python Code for Over Sampling via SMOTE
#Class to perform over-sampling using SMOTE
from imblearn.over_sampling import SMOTE, SMOTEN, SMOTENC
#also read about:
SMOTEN : Over-sample using the SMOTE variant specifically for categorical
features only.
SMOTENC : Over-sample using SMOTE for continuous and categorical features.
# creating the object of SMOTE
oversample = SMOTEN(sampling_strategy="minority", k_neighbors=5, random_state=100, n_jobs=-1)
#transform or resample/oversample the data
data_X, data_Y = oversample.fit_resample(X, Y)
Leave a Reply